

ai model deployment
MLOps
production AI
model serving
deployment strategy
AI Model Deployment: Expert Strategies to Deploy Successfully
Demystifying AI Model Deployment: Beyond the Algorithms

Deploying an AI model involves more than just a sophisticated algorithm. It's about successfully transitioning a theoretical model into a practical, real-world application. This critical step is often where promising AI projects encounter significant hurdles. Many underestimate the complexities of moving from a controlled research environment to the dynamic landscape of live operations.
This transition necessitates a change in perspective. The predictable nature of a development environment differs significantly from the unpredictable nature of real-world applications. For instance, development data is typically clean and well-structured. Real-world data, on the other hand, can be messy, incomplete, and ever-changing.
Understanding these challenges is crucial for successful AI model deployment. This involves considering the necessary infrastructure, organizational structure, and operational procedures for seamless integration into existing systems.
Key Considerations for Successful AI Model Deployment
Successfully deploying an AI model requires careful planning and execution. This goes beyond simply having a well-trained algorithm. It encompasses crucial aspects like robust infrastructure, organizational preparedness, and ongoing maintenance. Scalability should be a primary concern from the outset.
Consider whether your infrastructure can handle increasing data volume and user demand. Equally important is organizational readiness. Are your teams equipped with the skills and knowledge to effectively manage a deployed model? These considerations are as important as the technical aspects of deployment.
- Infrastructure: The infrastructure is the foundation of any AI deployment. A robust and scalable infrastructure is essential to handle the computational demands of the model in a production environment. Choosing the right architecture is a critical decision.
This might involve opting for cloud-based solutions, on-premise setups, or edge computing. The optimal choice depends heavily on the specific needs of the AI model and its intended purpose.
-
Organizational Readiness: Deploying an AI model is not just a technical endeavor, it’s also an organizational one. Teams must be ready to manage the deployed model effectively. This includes monitoring performance, addressing any arising issues, and iterating based on real-world feedback. This necessitates a shift in focus, emphasizing not just model development, but also continuous operation and maintenance.
-
Monitoring and Maintenance: The work doesn’t end after deployment. Continuous monitoring is critical to identify and address potential problems like model drift. Model drift occurs when a model's performance degrades over time due to changes in data patterns.
Regular updates and retraining are essential for maintaining long-term effectiveness. This ensures the model adapts to evolving data and continues to meet user needs.
This growing emphasis on AI model deployment is evident in the increasing investments in AI by businesses worldwide. A McKinsey survey reveals that 92% of companies plan to increase their AI investments over the next three years. This highlights the growing strategic importance of AI in business operations and decision-making.
Find more detailed statistics here: Explore this topic further. As AI plays an increasingly central role in business strategies, successfully navigating these deployment challenges is key for maximizing ROI and maintaining a competitive edge. This means organizations must adapt their strategies and invest in the necessary resources to ensure successful AI deployments.
Building the Technical Foundation for AI Model Deployment
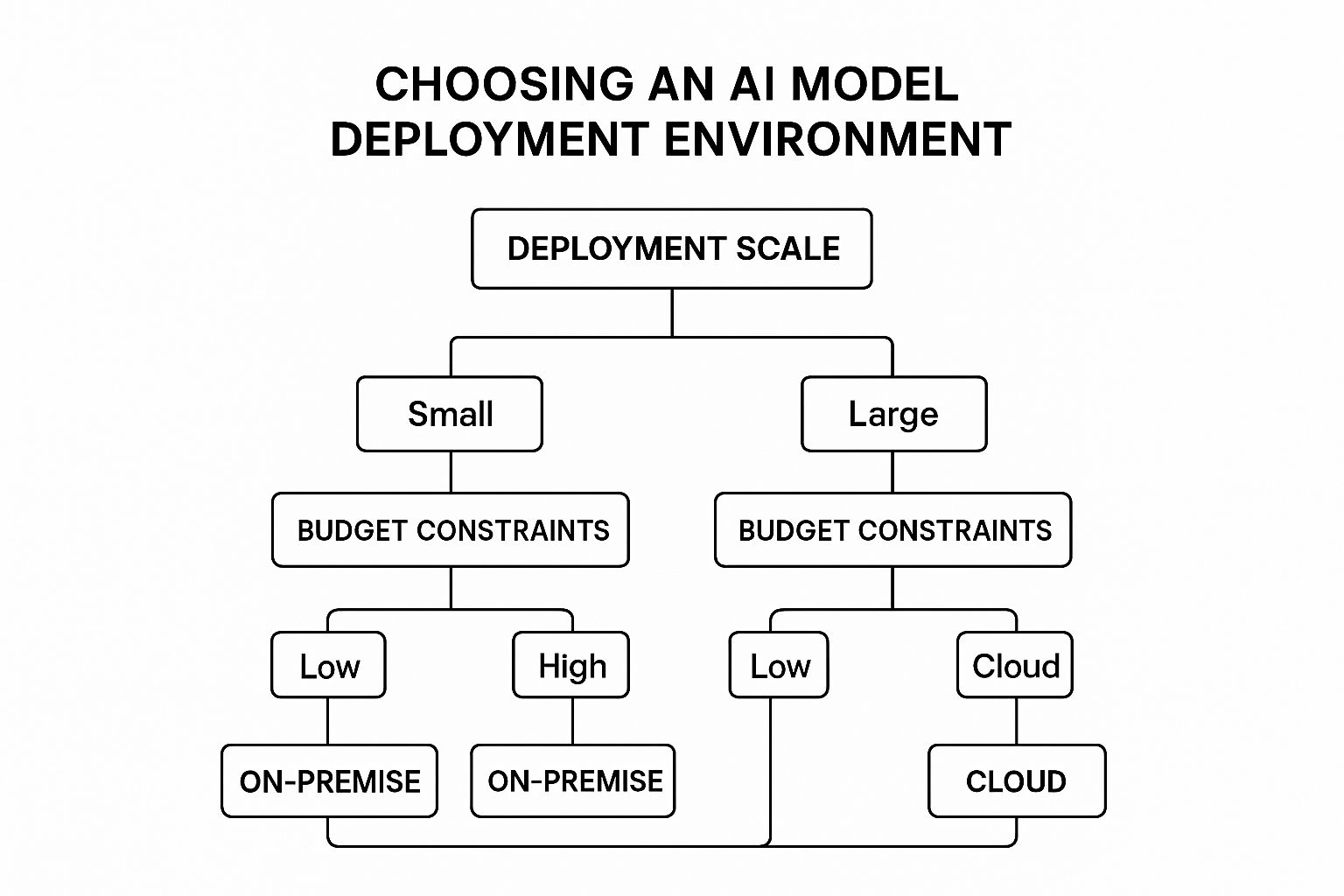
The infographic above illustrates how deployment scale and budget influence the choice of an AI model deployment environment. The ideal environment depends heavily on these two factors. Smaller projects with limited budgets may find on-premise solutions adequate, while larger projects with more resources might opt for cloud-based infrastructure. It emphasizes the importance of carefully assessing your needs before choosing a deployment strategy.
This section delves into the technical infrastructure crucial for successful AI model deployment. Choosing the right architecture is a vital first step. Deploying a complex model for real-time fraud detection, for instance, necessitates a different infrastructure than deploying a simpler model for offline customer segmentation. This involves making informed decisions about cloud versus on-premise solutions, containerization, and orchestration tools.
Choosing the Right Deployment Architecture
AI model deployment architectures range from simple on-premise setups to complex cloud-native solutions. Cloud platforms, like AWS, Azure, and Google Cloud, provide scalability and pre-built AI services, but may be more costly. On-premise solutions provide greater control and data security, but require significant upfront investment and ongoing maintenance. Edge computing brings AI processing closer to data sources, reducing latency and bandwidth needs. This makes it suitable for real-time video analysis or IoT devices. The best choice depends on the project's specific requirements.
For further insight into the algorithms driving AI model deployment, understanding AI model training can be beneficial. Explore resources like training a chatbot on your own data. You might also find How to master LLM pricing helpful.
Containerization and Orchestration
Containerization, using technologies like Docker, has become indispensable for AI model deployment. Containers package the model, its dependencies, and the runtime environment into a portable unit, facilitating deployment across various platforms. This portability minimizes dependency conflicts and ensures consistent performance across different environments.
Managing numerous containers effectively calls for orchestration. Kubernetes, a prominent orchestration tool, automates container deployment, scaling, and management. This automation is essential for managing complex AI deployments and guaranteeing high availability.
Model Serving Frameworks
Model serving frameworks are essential components of AI model deployments. They manage model loading, request handling, and resource allocation. Popular choices include TensorFlow Serving, TorchServe, and MLflow. Selecting the right framework depends on the model's specific requirements and desired performance characteristics. For instance, TensorFlow Serving is suitable for TensorFlow models, while TorchServe is designed for PyTorch models.
To illustrate the different platform options, the following table provides a comparison:
AI Model Deployment Platforms Compared: A detailed comparison of today's leading platforms for AI model deployment, highlighting their practical strengths, limitations, and ideal use cases
| Platform | Supported Frameworks | Scalability | Latency Performance | Monitoring Capabilities | Best For |
|---|---|---|---|---|---|
| AWS | TensorFlow, PyTorch, MXNet, etc. | High | Variable | Comprehensive | Large-scale deployments, diverse frameworks |
| Azure | TensorFlow, PyTorch, ONNX, etc. | High | Variable | Comprehensive | Enterprise applications, integration with Microsoft services |
| Google Cloud | TensorFlow, PyTorch, JAX, etc. | High | Variable | Comprehensive | Data-intensive applications, ML research |
| On-premise | Varies | Limited | Dependent on hardware | Varies | High security, regulatory compliance |
| Edge Devices | TensorFlow Lite, PyTorch Mobile, etc. | Low | Low | Limited | Real-time applications, limited connectivity |
This table highlights the diverse options available for deploying AI models, each with its own set of strengths and limitations. Choosing the appropriate platform is a crucial step in the deployment process.
Choosing the right technical foundation requires a comprehensive understanding of your business constraints, performance needs, and scalability requirements. Simpler solutions may suffice for some applications, while others require the flexibility and scalability of complex architectures. Careful evaluation of these factors is essential for successful AI model deployment.
Bridging Academic Innovation and Business Reality

The journey of an AI model from academic research to real-world deployment often reveals a stark contrast in priorities. Academia focuses on expanding theoretical knowledge and developing new algorithms. Industry, however, prioritizes operational resilience, cost-effectiveness, and a demonstrable impact on the bottom line. This creates a gap that must be bridged for successful AI model deployment. Understanding these different priorities and building effective collaboration models is essential for navigating this transition.
From Algorithm to Application: Translating Research into Reality
Translating academic breakthroughs into deployable AI solutions requires a significant shift in mindset. Academic research thrives in controlled environments, using clean data and tackling well-defined problems. Real-world deployments, on the other hand, encounter messy, incomplete data and unpredictable conditions.
For example, imagine an image recognition model trained on a carefully curated dataset. This same model might struggle with the varied lighting and angles encountered in a real-world security application. Adapting these models to handle such complexities is a key element of successful deployment. Furthermore, industry teams must address factors like scalability, maintainability, and security. These are often secondary concerns in academic research. This demands careful planning of the deployment architecture and infrastructure. Choosing between cloud, on-premise, or edge deployment, for example, depends on understanding the specific requirements and limitations of the application.
Collaboration Models for Success: Bridging the Divide
Organizations that excel at AI model deployment cultivate collaboration between researchers and engineering teams. This creates a beneficial cycle where production challenges inform research directions, and theoretical innovations enhance deployment capabilities. Open and effective communication is vital for this cycle to thrive.
One successful model involves embedding researchers within engineering teams. This ensures direct communication and a shared understanding of project goals. Another approach uses regular knowledge-sharing sessions and joint workshops to bridge the gap between theory and practice. Building these robust communication channels creates a constant feedback loop between research and application, allowing research findings to be quickly adapted to real-world challenges.
Building a Virtuous Cycle: Production Challenges Informing Research
The challenges encountered in production environments can provide invaluable insights for researchers. This feedback loop can inform the development of more robust and practical models. For example, if a deployed model struggles with particular data anomalies, this highlights the need for research into algorithms that can better handle such inconsistencies. Check out our guide on generating micro SaaS ideas for further inspiration.
Industry and academia play distinct but complementary roles in AI model development and research. Interestingly, industry has emerged as the leading force in creating notable AI models, with almost 90% originating from industry in 2024, up from 60% in 2023. Meanwhile, academia maintains its role as a key contributor to highly cited research. The collaboration between these two forces remains essential for the continued advancement of AI technologies. Discover more about this trend.
Through this continuous feedback loop, organizations can create a virtuous cycle where practical challenges drive research innovation. This ensures AI models are not just theoretically sound, but also practically applicable. This iterative process ultimately accelerates the overall advancement of AI technology.
MLOps: Turning AI Model Deployment into a Repeatable Process
Deploying AI models can be a complicated and unpredictable undertaking. MLOps, a set of practices designed to streamline this process, offers a more reliable and repeatable approach. Leading organizations are adopting MLOps frameworks to gain consistency and scalability in their AI initiatives, shifting away from ad-hoc methods toward a more systematic and engineered strategy.
Automating the AI Model Deployment Pipeline
MLOps brings automation to the AI model deployment pipeline, significantly reducing deployment times and improving reliability. Some organizations have seen deployment times fall from months to mere days, enabling faster responses to changing market conditions and new opportunities. Automation also minimizes human error, a frequent source of problems in manual deployments.
-
Continuous Integration and Continuous Delivery (CI/CD): CI/CD pipelines automate the building, testing, and deployment of AI models, allowing for rapid iteration and faster time to market. With CI/CD, changes to the model or its code are thoroughly tested and smoothly integrated into production.
-
Automated Testing: Automated testing is critical for maintaining quality and reliability. Tests verify model accuracy, performance, and robustness in different scenarios. This continuous evaluation identifies and addresses potential issues before they impact users.
-
Automated Monitoring and Alerting: Continuous monitoring tools track key metrics of deployed models, alerting teams to performance drops or unexpected behavior. This allows for proactive intervention and helps prevent model drift, where a model's accuracy declines over time due to changes in input data.
Key Components of Mature MLOps Practices
Mature MLOps goes beyond basic automation, encompassing several key components for reliable and scalable AI model deployment. These components address the broader aspects of model lifecycle management.
-
Version Control for Code and Data: Tracking changes in both code and data is essential for reproducibility and understanding a model's evolution. This enables easy rollback to previous versions if needed.
-
Model Registry: A central repository, or model registry, for trained models simplifies model management. A registry makes it easy to access model versions, track their performance, and deploy them to different environments.
-
Monitoring Systems for Model Drift: Implementing monitoring systems that proactively detect and alert on model drift is essential. Early detection helps mitigate the negative business impacts of drift.
To better understand the metrics organizations use for success with their deployed AI models, the table below offers a breakdown of key performance indicators:
Critical Metrics for Deployed AI Model Success Essential performance indicators that leading organizations track to ensure their deployed AI models deliver continued business value while maintaining reliability
| Metric Category | Specific Metrics | Importance | Optimal Monitoring Frequency | Warning Signs |
|---|---|---|---|---|
| Performance | Accuracy, Precision, Recall, F1-score, AUC | Crucial for evaluating model effectiveness | Continuous/Real-time | Significant drop in metrics, inconsistent predictions |
| Business Impact | Revenue lift, Cost reduction, Customer satisfaction, Conversion rate | Directly tied to business goals | Daily/Weekly | Failure to meet business objectives, negative customer feedback |
| Operational Efficiency | Inference latency, Throughput, Resource utilization | Ensures efficient resource allocation and responsiveness | Continuous/Real-time | Increased latency, decreased throughput, high resource consumption |
| Model Health | Model drift, Data quality, Feature importance stability | Detects potential issues that impact long-term performance | Continuous/Daily | Drift exceeding thresholds, data anomalies, shifting feature importance |
| Security | Unauthorized access attempts, Data breaches, Model tampering | Protects sensitive data and model integrity | Continuous | Suspicious activity, security alerts |
This table highlights the diverse metrics used to ensure AI models continue to deliver value and remain reliable after deployment. From performance measures like accuracy to security considerations, continuous monitoring and proactive responses to warning signs are crucial for long-term success.
Balancing Governance and Deployment Velocity
Organizations must balance governance needs with the desire for fast deployment. Strong governance practices ensure responsible AI development and deployment without sacrificing speed to market.
-
Establishing Clear Governance Policies: Well-defined policies guide model development, deployment, and monitoring, ensuring compliance with ethical considerations and regulations.
-
Implementing Robust Security Measures: Security is paramount for any AI deployment. Organizations must protect the sensitive data used by the model and prevent unauthorized model access.
-
Building Observability into Systems: Systems designed with observability in mind allow for improved monitoring, troubleshooting, and understanding of model behavior. This helps identify potential issues early and speeds up debugging.
MLOps offers practical approaches for organizations at all maturity levels, helping them build robust, reliable, and repeatable AI deployment processes. While implementing these practices can present challenges, the benefits of improved deployment speed, reliability, and governance make MLOps a key consideration for any organization serious about AI.
Taming the Complexity of Generative AI Deployment

Generative AI models offer incredible power, but deploying them presents unique challenges beyond those of traditional machine learning models. Factors like computational costs, ethical considerations, and integration strategies require careful planning. Let's explore how organizations are successfully navigating these complexities to bring generative AI into production.
Addressing the Computational Economics of LLMs
Large Language Models (LLMs) require substantial computational resources, which can be a barrier to deployment. To overcome this, innovative teams are using several strategies. Model distillation, for example, creates smaller, more efficient models that retain most of the original model's power. Think of it like condensing a massive textbook into concise, yet comprehensive, notes.
Another approach is inference optimization. This focuses on making the process of generating output from the model more efficient, significantly reducing the computational resources needed for each request. The result? Cost savings for organizations using these models. These optimization techniques make deploying and running generative AI more affordable.
Furthermore, the increasing use of generative AI highlights the need for efficient deployment strategies. Adoption rates have doubled to 65% in just one year (2023-2024). This growth is fueled by its potential to revolutionize business, particularly in customer service, where 59% of companies see it as crucial for enhancing customer interactions. Despite this progress, challenges still exist. Learn more about this trend: Find more detailed statistics here.
Implementing Responsible AI Guardrails
Responsible generative AI deployment requires protective measures. These AI guardrails safeguard both users and organizations from potential harm and unintended consequences. This involves establishing mechanisms to prevent the generation of harmful or biased content. For example, content filtering systems can help screen outputs for inappropriate language and misinformation.
Access control is another critical element. By restricting access to the model, organizations can prevent unauthorized use and protect sensitive data. This multi-layered security approach is essential for maintaining trust and minimizing the risks associated with generative AI.
Integrating Generative Capabilities into Existing Systems
Integrating generative AI into existing systems and workflows requires careful architectural planning. Many organizations are adopting hybrid architectures, which combine different types of models. This approach allows them to leverage the strengths of each model while minimizing their individual weaknesses.
For example, a business might combine a generative model for content creation with a traditional machine learning model for sentiment analysis. This combination lets them generate creative content while also evaluating its potential impact on customer perception. This strategic integration maximizes the benefits of both models. By strategically combining models, companies can improve overall system performance and take advantage of the unique capabilities of different AI technologies.
Scaling AI Model Deployment Across The Enterprise
Scaling AI model deployment from pilot projects to an enterprise-wide strategy requires a well-structured approach. Many organizations underestimate the complexities involved in making this transition. This section explores how successful companies build the organizational capabilities needed for AI at scale, covering architectural patterns, team structures, and robust governance frameworks.
Architectural Patterns For Scalable Deployment
Deploying AI models consistently across multiple business units requires careful planning and consideration of architectural patterns. Feature stores, for instance, serve as centralized repositories for data features, thus promoting reusability and consistency across different models and teams. This minimizes redundant work and ensures that everyone operates from the same foundational elements.
Model registries act as a central hub for managing deployed models, including tracking different versions, performance metrics, and all associated metadata. Think of it as a comprehensive library catalog for your AI models. This allows teams to easily discover and reuse existing models, accelerating the development process and ensuring effective governance. These tools simplify the management and tracking of models throughout their entire lifecycle.
Structuring Teams For AI Success
Building successful teams for enterprise-wide AI deployment requires finding the right balance between centralized expertise and decentralized implementation. A central AI team provides specialized knowledge, shares best practices, and offers essential support across the organization. This team functions as a center of excellence, guiding and supporting other teams in their AI initiatives.
Equally crucial, however, is empowering individual business units to adapt and deploy models tailored to their specific needs. It’s akin to a franchise model: the central team provides the framework and support, while individual franchises tailor their operations to the nuances of their local market. This blend of centralized support and decentralized implementation allows organizations to scale their AI initiatives effectively.
You might be interested in: How to master building an AI app.
Governance Frameworks For Responsible AI
Scaling AI deployment necessitates robust governance frameworks to address the complex challenges of managing numerous models in a production environment. These frameworks provide vital guidance for risk mitigation and ensure responsible AI practices are followed.
A clear governance structure should define roles and responsibilities related to model development, deployment, and ongoing monitoring. It’s like establishing traffic laws for a busy city: clear rules and responsibilities are crucial for ensuring smooth operations and everyone's safety. For example, specific individuals or teams should be designated for approving models for deployment and for monitoring their performance.
Real-world governance frameworks often incorporate key principles of explainability, fairness, and transparency. This involves understanding how a model arrives at its decisions, ensuring its predictions are free from bias, and providing clear documentation about its intended purpose and any limitations. Think of this like providing nutritional labels for food products: consumers deserve to know what they’re using and its potential impact.
Successfully navigating these challenges demands strategic planning and a long-term vision. By adopting robust architectural patterns, building effective teams, and implementing clear governance frameworks, organizations can fully realize the potential of AI across the enterprise. Addressing these key areas paves the way for scalable and successful AI model deployment. This structured approach enables companies to effectively manage the increasing complexity of dozens or even hundreds of models in production, maximizing the benefits of AI while simultaneously minimizing potential risks.
The Future of AI Model Deployment: Emerging Trends
The AI model deployment landscape is constantly changing. New trends promise to reshape how we bring models to production, offering exciting possibilities for improved efficiency, scalability, and accessibility. Let's explore some key trends shaping the future of AI model deployment.
Serverless Deployments: Reshaping AI Infrastructure Economics
Serverless deployments are transforming the economics of AI infrastructure. They allow developers to deploy models without managing servers, offering significant cost savings by charging only for compute resources consumed during model execution. Think of it like paying for electricity only when a light is on, not continuously regardless of usage.
This on-demand nature makes serverless deployments perfect for applications with fluctuating workloads. Serverless platforms also typically handle scaling automatically, allowing models to handle sudden spikes in demand without manual intervention. This flexibility makes them a highly attractive option.
Edge Computing: Bringing AI to the Data Source
Edge computing brings AI model deployment closer to the data source, opening up exciting new possibilities. Running models directly on edge devices reduces latency and bandwidth requirements – critical for applications like real-time video analysis and IoT devices. Consider self-driving cars, where immediate processing of sensor data is essential.
This localized processing also enhances data privacy by minimizing the need to transmit sensitive information to central servers. Furthermore, edge computing enables AI applications in areas with limited or no internet connectivity, broadening the reach of AI-powered solutions.
Federated Learning: Collaborative AI with Enhanced Privacy
Federated learning addresses growing privacy concerns while enabling the development of more robust AI models. This approach trains models across multiple decentralized devices or servers holding local data samples, without exchanging those samples directly. Imagine multiple chefs perfecting a recipe independently, each contributing improvements without revealing their complete ingredient list.
This allows organizations to leverage diverse datasets while maintaining data privacy and confidentiality. Federated learning is particularly relevant in sectors like healthcare, where data privacy regulations are strict. It's a promising method for creating powerful collaborative models without compromising data security.
AutoML: Democratizing AI Model Deployment
AutoML is making AI model deployment more accessible. By automating key steps in the model development process – like feature engineering, model selection, and hyperparameter tuning – AutoML reduces the need for specialized expertise. This opens the world of AI to individuals and organizations without dedicated data science teams.
AutoML tools empower individuals and organizations to quickly build and deploy effective models without extensive machine learning knowledge. This democratization of AI has far-reaching implications across numerous industries.
Explainable AI: Enhancing Transparency and Trust
As AI models become more complex, the need for explainability grows. Explainable AI (XAI) aims to make model decisions more transparent and understandable, building trust and facilitating human oversight. This is crucial for sensitive applications like loan approvals or medical diagnoses.
Imagine a doctor understanding not only the diagnosis suggested by an AI, but also the reasoning behind it. XAI techniques provide insights into the factors influencing model predictions, enabling users to identify potential biases, verify model behavior, and make informed decisions based on AI outputs. This transparency is essential for responsible AI development.
These emerging trends offer a glimpse into the future of AI model deployment. As technology continues to advance, we can anticipate new approaches and innovations that will further transform the landscape of AI deployment. Staying informed about these advancements is key to unlocking the full potential of AI.
Ready to jumpstart your AI project development? AnotherWrapper provides a comprehensive AI starter kit with pre-built applications and essential services, enabling you to focus on innovation and launch your AI-powered projects faster. Explore AnotherWrapper and start building today!
Fekri


