

vector search example
semantic search
embedding models
AI implementation
search technology
Vector Search Example: Build Smarter Search Systems
Beyond Keywords: Understanding Vector Search Fundamentals

Traditional search relies on matching keywords. This method, however, can sometimes miss the mark when it comes to understanding the real meaning behind a search. For example, someone searching for "best running shoes for marathon training" might not see results for "long-distance running footwear recommendations." The intent is similar, but the keywords are different.
This is where vector search enters the picture. Instead of simply matching keywords, vector search focuses on understanding the meaning and context of the words within a search query.
Vector search uses embeddings, which are mathematical representations of data. These embeddings can represent text, images, or other types of data, capturing their semantic meaning. Essentially, embeddings translate words and phrases into vectors within a multi-dimensional space. Similar concepts are clustered close together, while dissimilar concepts are farther apart.
Think of it this way: "running shoes" and "sneakers" would be positioned near each other in this vector space because they have similar meanings. This spatial arrangement helps vector search find relevant results even when they don't use the exact same keywords as the search query. It's a search for meaning, not just a matching game.
How Does Vector Search Work?
Let's illustrate vector search with an example. Imagine you're searching for information on "electric vehicles." First, the search engine converts your query, "electric vehicles," into a vector. Then, it compares this vector to the vectors of all the documents in its index.
The documents with vectors closest to your query vector are considered the most relevant and are returned as search results. This "closeness" is determined using similarity metrics, the most common being cosine similarity. Cosine similarity measures the angle between two vectors. A smaller angle indicates a higher degree of similarity.
Why Is Vector Search Gaining Traction?
The shift toward semantic and hybrid search requires a new kind of infrastructure. This infrastructure needs to be able to generate embeddings in real-time and handle massive amounts of data. As a result, companies are investing in ways to balance traditional databases with vector databases. This balance helps create more responsive and insightful information systems.
The growing adoption of vector search within various data strategies underscores its importance, particularly for applications powered by AI. By 2025, it's expected that marketers will increasingly rely on vector search. They'll use it to improve content recommendations and personalization, both crucial for creating context-aware customer experiences. Learn more about the impact of vector search in marketing here. This shift is changing how businesses analyze their data and interact with their customers.
This basic understanding of vector search principles reveals why it's quickly becoming the go-to method for delivering search results that truly align with what users are actually looking for.
Your First Vector Search Implementation: A Step-by-Step Guide
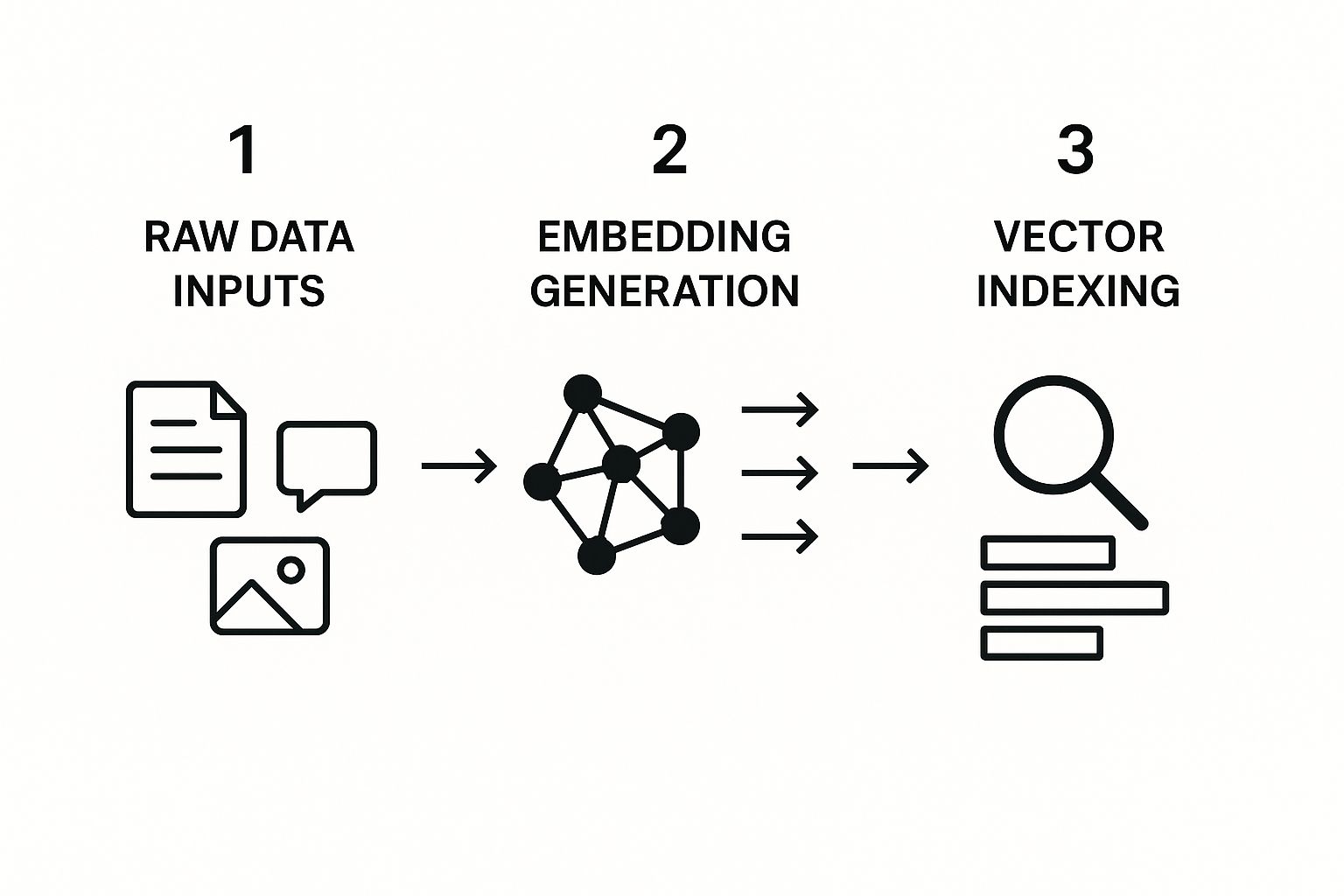
This infographic illustrates how vector search works. It shows the journey from raw data to searchable vectors, highlighting how these steps are connected. This transformation is key to unlocking the power of semantic search. Let's explore a practical implementation.
Choosing Your Embedding Model
The first step is choosing the right embedding model. This model transforms your raw data into vectors. Libraries like TensorFlow and PyTorch offer pre-trained models for different data types. If you're working with text, models like Sentence-BERT are designed for generating sentence embeddings.
Generating and Storing Embeddings
After selecting a model, you can generate embeddings for your data. This involves feeding your data through the model, which outputs vector representations. These vectors need to be stored efficiently. Supabase is one platform that offers built-in support for managing vector embeddings, simplifying integration into your application. For more insights on related techniques, you might find this helpful: How to master prompt engineering with AnotherWrapper.
Implementing the Search Functionality
Once your embeddings are stored, you can implement the search functionality. This involves taking a user's query, generating its embedding using the same model, and comparing it to the stored vectors. Libraries like Faiss and Annoy offer efficient methods for similarity searches, like finding the nearest neighbors to the query vector. This retrieves the most relevant results.
Optimizing for Performance
For larger applications, optimizing performance is crucial. Techniques like dimensionality reduction can significantly improve search speed without sacrificing much accuracy. Methods like PCA (Principal Component Analysis) reduce the size of the vectors, preserving essential information. This smaller size means faster searching and less storage. For further refinement, you might consider tools like Twitter Advanced Search to improve information retrieval.
Example: Searching for Similar Products
Imagine an e-commerce platform with product descriptions. You could use an embedding model to create vectors for each description. When a user searches for "red running shoes," the system generates an embedding for this query and searches for the nearest neighbor vectors among the product embeddings. The products linked to those nearest neighbors appear as results, even if they don't specifically mention "red" or "running." This creates more nuanced and context-aware search experiences. Building a practical vector search example requires understanding these steps.
The following table provides a comparative overview of different implementation approaches, highlighting their strengths and weaknesses:
Vector Search Implementation Approaches Compared A practical comparison of implementation methods to help you choose the right approach based on your specific project requirements and constraints
| Implementation Method | Complexity Level | Performance | Scalability | Best Use Cases |
|---|---|---|---|---|
| In-memory libraries (e.g., Faiss, Annoy) | Low to Medium | High | Limited by RAM | Small to medium datasets, rapid prototyping |
| Disk-based solutions (e.g., ScaNN) | Medium to High | Moderate | High | Large datasets, applications requiring persistence |
| Cloud-based vector databases (e.g., Pinecone, Weaviate) | Low | High | High | Production-ready applications, managed infrastructure |
This table summarizes key considerations when choosing a vector search implementation method. Consider factors like dataset size, performance needs, and scalability requirements when making your decision. Choosing the correct method will ensure efficient and effective search functionality.
Vector Search in Action: Real-World Success Stories

Vector search is changing the way businesses connect with their customers, offering a more intuitive and effective search experience. It moves beyond simple keyword matching to understanding the actual meaning and intent behind a user's query. Let's explore some practical examples of how vector search is making a difference.
E-Commerce: Refining Product Discovery
Imagine searching for the perfect winter sweater on an e-commerce site. A traditional keyword search for "cozy winter sweater" might miss relevant results like "warm knitted pullover." Vector search, however, understands the semantic relationship between these phrases. By recognizing the underlying intent, it can retrieve a wider range of suitable items, ultimately boosting conversion rates and improving the overall shopping experience.
Content Platforms: Personalizing the User Journey
Content platforms use vector search to deliver highly personalized recommendations. By representing user profiles and content as vectors in a shared space, the platform can identify similar users and suggest content they are likely to enjoy. This creates a more engaging experience, encouraging users to return for more tailored content that aligns with their specific interests.
Healthcare: Accelerating Medical Research
Healthcare professionals often need to access critical information quickly. Vector search helps them navigate vast medical databases with ease, retrieving relevant documents based on semantic similarity rather than just keywords. This accelerates research, assists in diagnosis, and can ultimately lead to better patient care. Using vector search, finding a specific medical case study within a vast archive becomes significantly simpler.
Financial Services: Enhancing Fraud Prevention
In the financial world, detecting fraudulent activities is paramount. Vector search assists by analyzing transaction patterns and identifying anomalies. By comparing transaction embeddings, it can flag suspicious activity that deviates from established norms, helping protect both businesses and customers from financial crimes.
The Growing Impact of Vector Databases
The adoption of vector databases underscores the increasing need for advanced data analysis. The market is projected to reach $3.04 billion by 2025, growing at a CAGR of 23.7%. This growth is further projected to reach $7.13 billion by 2029, driven by the increased use of cloud services that allow for faster processing of large datasets. For more in-depth market analysis, you can find detailed statistics here.
Support Services: Optimizing Knowledge Base Utilization
Customer support teams rely on knowledge bases to quickly resolve user issues. Vector search empowers support agents to find the most relevant information even when user queries are phrased differently. This leads to faster resolution times and increased customer satisfaction, streamlining the entire support process.
These are just a few examples of how vector search is transforming industries. Its capacity to grasp context and semantics makes it an invaluable tool for enhancing search experiences and opening new avenues for data analysis. As the technology continues to develop, its applications are only expected to broaden.
Performance Optimization: Making Vector Search Lightning Fast
Optimizing vector search is essential for achieving both speed and efficiency, especially when dealing with large datasets. A well-optimized system ensures rapid response times, crucial for a seamless user experience, even with billions of vectors. This responsiveness is the key to user engagement and satisfaction in any application using vector search.
Dimensionality Reduction: Balancing Speed and Accuracy
High-dimensional vectors can be computationally intensive. Dimensionality reduction techniques offer a solution. Methods like PCA (Principal Component Analysis), t-SNE (t-distributed Stochastic Neighbor Embedding), and UMAP (Uniform Manifold Approximation and Projection) reduce the number of dimensions while striving to preserve essential information.
This smaller vector size leads to faster search speeds and lower storage needs. Choosing the right technique depends on the specific data and the required level of accuracy. Each method has its strengths and weaknesses concerning information preservation and computational cost.
Approximate Nearest Neighbor (ANN) Algorithms: Scaling for Billions of Vectors
For massive datasets, Approximate Nearest Neighbor (ANN) algorithms are indispensable. These algorithms, like those found in libraries such as Faiss and Annoy, offer a fast method for finding similar vectors without needing to search the entire dataset.
This allows vector search to scale effectively to billions of vectors, balancing speed and accuracy. ANN algorithms sacrifice some accuracy for significant speed improvements, making them essential for large-scale applications.
Caching, Hardware, and Index Structures: Fine-Tuning Your System
Optimizing caching mechanisms can drastically improve performance. Storing frequently accessed vectors in memory reduces retrieval time. Specialized hardware, like GPUs, can further accelerate processing, particularly for similarity calculations.
The choice of index structure is also critical. Options like tree-based indexes or hashing-based indexes offer different trade-offs between speed and accuracy. Choosing the right combination of caching, hardware, and indexing is key to maximizing performance. You might be interested in: How to master database performance optimization.
Benchmarking and Real-World Examples: Measuring Improvement
Continuous benchmarking helps evaluate optimization efforts and pinpoint bottlenecks. Key metrics include query latency, throughput, and recall. These provide valuable insights into system performance.
By analyzing these metrics and comparing different optimization strategies, you can identify the best approach for your needs. Real-world examples offer further guidance on how other organizations have optimized their vector search systems.
To illustrate the importance of various metrics, let's take a look at the following table.
The table below, "Vector Search Performance Benchmarks," presents essential metrics for evaluating and optimizing your vector search implementation. These metrics, coupled with the optimization techniques described, offer a pathway to improve search performance and achieve optimal results.
| Metric | Description | Typical Values | Optimization Techniques |
|---|---|---|---|
| Query Latency | Time taken to process a single search query. | Milliseconds to seconds depending on data size and system configuration | Caching, ANN algorithms, optimized index structures, hardware acceleration |
| Throughput | Number of queries processed per unit of time. | Queries per second (QPS) | Hardware acceleration, parallel processing, efficient indexing |
| Recall | Proportion of relevant vectors retrieved in a search. | Percentage (e.g., 90%) | Choice of ANN algorithm, parameter tuning, dimensionality reduction |
As the table illustrates, optimizing vector search involves a multifaceted approach. By carefully considering each metric and implementing appropriate techniques, significant performance gains can be achieved, leading to a more responsive and efficient search experience.
Vector vs. Traditional Search: When to Use Each Approach
While vector search offers powerful advantages for understanding context and meaning, traditional keyword search still has its place. Selecting the right approach—or even combining both—depends on understanding their individual strengths. This knowledge allows you to create a search strategy for optimal results.
When Vector Search Shines: Understanding Context and Meaning
Vector search excels with complex queries where grasping the user's intent trumps matching specific keywords. Imagine a user searching for "best laptops for graphic design." A traditional keyword search might focus solely on those exact words, overlooking relevant results like "top computers for visual artists."
A vector search, however, understands the underlying concepts. It retrieves results related to high-performance laptops suitable for creative work, regardless of the precise wording. Vector search also effectively handles synonyms, recognizing that "large" and "big" have similar meanings.
The Power of Traditional Search: Precise Keyword Matching
Traditional keyword search remains essential for precise matching. Think about searching for a specific product code or a formal document title. In these scenarios, exact wording is paramount, and the nuanced understanding of vector search might be less critical. This type of search is especially helpful with structured data where keywords reliably pinpoint the needed information. You might be interested in resources like How to master AI and chatbots with AnotherWrapper for further exploration.
Hybrid Approaches: Combining the Best of Both Worlds
Many organizations now use hybrid search systems, combining the best of both vector and traditional search. This often involves using keyword search for filtering and vector search for ranking. A user could filter products by category using keywords and then have those results ranked by relevance using vector search. This provides both precision and nuanced understanding.
The Global Expansion of Vector Search
The increasing importance of vector search is evident in market trends. North America currently dominates the vector database market, with 39% of the revenue share, largely due to substantial AI investment and strong cloud infrastructure. However, the Asia-Pacific region is projected to have the fastest growth, fueled by rising AI research and digital transformation efforts. More detailed statistics can be found here. This global growth underscores the expanding role of vector search in optimizing data management and analysis across various industries.
By carefully considering your search application's needs, you can choose the most effective strategy—vector, traditional, or hybrid—to deliver the best possible search experience. This ensures your resources are invested effectively, maximizing user satisfaction and achieving business objectives.
What's Next: Emerging Trends in Vector Search Technology
Vector search technology is constantly evolving, pushing the boundaries of information retrieval. Several key trends are shaping the future of this field, promising even more powerful and adaptable search capabilities. These advancements aren't just theoretical; they're actively being implemented, changing how businesses operate and users interact with information.
Multimodal Vector Search: Breaking Down Data Silos
One of the most exciting developments is multimodal vector search. This approach removes the traditional barriers between different data types, allowing for a unified search experience across text, images, audio, and video. Imagine searching for "red shoes" and getting results that include not only product descriptions but also pictures and videos of red shoes. This capability is increasingly important as the volume of diverse data continues to grow.
Self-Supervised Learning: Democratizing Embedding Models
Creating high-quality embedding models often requires significant amounts of labeled data, which can be expensive and time-consuming to acquire. Self-supervised learning offers a solution by allowing models to learn from unlabeled data. This simplifies and makes it more affordable to create specialized embedding models for specific fields, opening new possibilities for vector search applications. Wider access to these specialized models can greatly improve search accuracy in niche areas.
Specialized Hardware and Cloud-Native Vector Databases: Reducing Implementation Costs
The development of specialized vector processing hardware and cloud-native vector databases is significantly reducing the cost and complexity of implementing vector search. This makes the technology available to a wider range of organizations, from small startups to large enterprises. This increased accessibility is driving wider adoption and encouraging further innovation. For those interested in the factors influencing startup acquisitions, this article provides valuable insights: predict the odds of your startup getting acquired.
Vector Search and Generative AI: A Powerful Partnership
Vector search is becoming a core component of generative AI systems and large language model (LLM) applications. It allows these systems to access and process huge amounts of information, enabling them to generate more relevant and contextually appropriate responses. This integration is essential for creating more sophisticated and helpful AI-powered experiences. It allows LLMs to base their responses on factual data, improving accuracy and dependability. This combination of vector search and generative AI is poised to transform how we interact with information and technology.
Ready to explore the power of vector search and other AI tools? AnotherWrapper offers a comprehensive platform to build and launch AI-powered applications quickly and efficiently. Discover how AnotherWrapper can accelerate your next AI project.
Fekri



